Some thoughts on human memory
Disclaimer: The thoughts expressed here are based on my own readings and understanding and not based on through research. I write them down just as a journal of ideas that I think of or come across
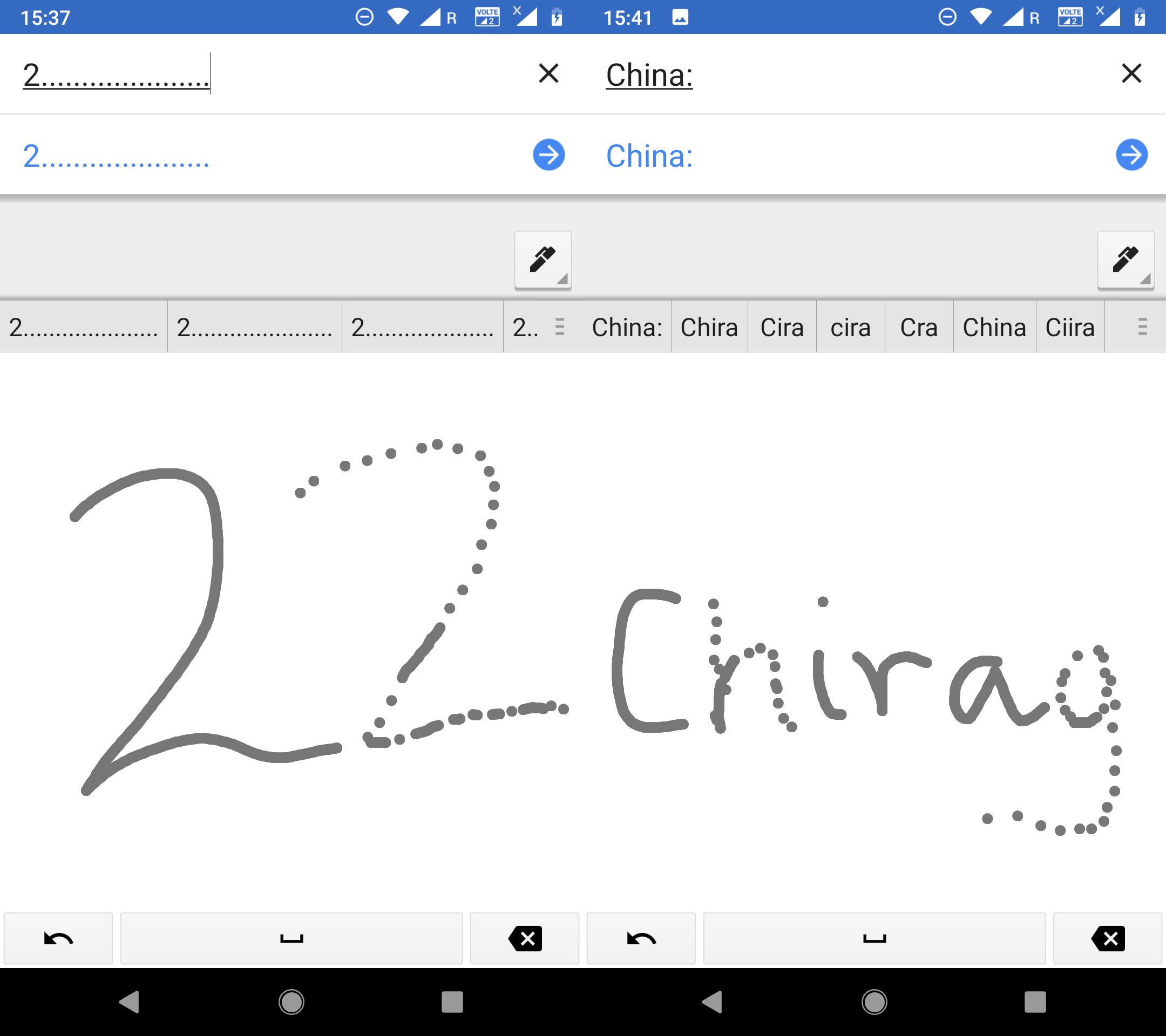
Google Translate Handwriting Recognition Fails
Computers were built to do what humans could not. However there is an increasing need and tremendous impact of building systems that do what humans (animal kingdom) can best do. We have mastered the engineering of systems that compute fast, accurately and on large data. But inspite of interesting developments in recent times, we are still very far from understanding human-like or in general biological-systems-like computing. Shown in the figure is my simple attempt at fooling Google's handwriting recognition system. It can not connect the dots.
I had attended a summer school on computational neuroscience at National Center for Biological Sciences, Bangalore. Prof. Misha Tsodyks from the Weizmann Institute gave a talk on cognitive modelling of the process of recall from memory. In particular an observation he presented stuck with me. When given a list of 20 'unrelated' objects and asked to remember them, its hard for us to recollect more than some 10-12 of them. However its very easy to answer if a particular object belonged to the list. This simple example indicates how our memory is so different that the silicon memories we have built. Both the task would be of similar complexity in time and hardware for a silicon memory (O(n)). Further, the word 'unrelated' is important. If the words were related like 'shirt' and 'jeans' or 'lunch' and 'dinner', our ability to recall increases significantly. Also, what is 'related' depends from person to person, influenced by past experiences. For instance, I may relate 'white' with 'dog' because my dog is white in colour. Of course brain's fondness for patterns in well known. See this NatGeo series that shows how a chess grandmaster is good at recalling pattern of chess pieces, but only if they appear in familiar chunks as it would in a real game. This is in contrast to most machine memories where storing an array doesn't really care about contents of the array, but only about its size. This however is not entirely true because the algorithms we us for compressing the data to be stored in those memories rely heavily on patterns in data. While compression is beneficial to have in machine storage, seems like patterns are crucial for how memory in our brain works. Nature enabled us to find the most important cues in a scene and remember them quickly for survival in the wild world. And hence identifying cues and compressing information became, not just a feature, but the core of how we remember. So what is the difference between machine and brain compression methods? The scale. Compression algorithms mostly depend on character or pixel level patterns, while brain depends on object level or the 'semantics' of the data.
In this context, it was nice to see this work from Prof. Taschy Weissman's group at Stanford. Summarily, the experiment uses human agents to describe an image, and this description in words is considered a compressed version of the image to the extent that another human can reconstruct a humanly appealing version of the original image from those descriptions. To aid the process, images publicly available from google are used as references with their links being part of the text. The entire process is like detailed captioning of the image. The brain essentially does segmentation, object identification, context identification, fits everything into a description shedding away details it finds not important, all rolled into one. We today have good artificial systems that do the same like this caption bot. While these deep learning based systems emulate the brain well to some extent, they do not easily reveal what is happening. So the key question is how can we use fundamental theories and tools to model the process of cue retrieval, compression and memory in the brain. One thing that immediately comes to my mind is Information Theory.
The first time I heard of Information theory, I was excited to see how do we quantify information or 'meaning' conveyed by a sentence or an image. To my utter dismay, Information Theory was firmly based on the principle of ignoring semantics. Shannon specifically mentions it very early on in his seminal paper. It took me some time to realize how fundamentally amazing and important this insight of Shannon was. 'Meaning' is a very human thing. Communication systems had no business with 'meaning' of the data. Only the symbols and their pattern mattered. Ignoring semantics enabled a systematic and useful definition of information. Intutively, the definition of information valued rarity. Rare information is more useful information. This served the communication and other systems well, where loosely speaking compressing data and optimising it to occupy as less resources as possible was an important consideration. But brain's objectives are different. More than size, it probably values fast encoding and decoding more. Besides it has a large prior experience and information that it can use. So can we quantify 'meaning' in an information like it matters to the brain? Seems like it has been explored with many attempts to use classical information theory in psychology and related fields, until the skepticism set in (example). Shannon himself was critical of use of Information Theory at places and ways in which it was not intended for. But now the times have changed. We have more data, more resources, more ideas. It would be exciting to have a re-look, through the prism of Information Theory or otherwise.
The above experiment draws a good analogy with the brain. My brain overtime has seen so many objects and scenes that when I come across a new one, it tries to relate it to something I have seen before. The huge database that sits in my brain is akin to Google's collection of images. The experiment calls for use of this large pool of data, very human-like. Each object I know can be thought of as a symbol. When I see a new object, I encode it in terms of these symbols, and the object becomes a new symbol in my memory. So, I probably create a dense network of objects in my mind, and and expanding set of symbols. In effect, I am only storing what the relation of new object to the old ones and any significant differences there might be. To take a walk along this netowrk, it is an interesting intellectual exercise to track your thoughts. Look at a random word and observe what are the things that first come to your mind and how one idea links to another and another. For instance, on seeing the word 'bond', I immediately think of '007', gun, tuxedo etc, a little more thought and I think of 'love', as in bond between two people (it helps that bond movies had romance). And then as I think of bond 'between' people, I think of chemical bonds and so on. It may proceed very differently for you. The previous thoughts acts like a retrieval cue to open a new one. Can we model this? Can we quantify 'meaning' in such information? It would require some creativity to think how. For example, in language of the brain, an image of a giraffe has less information than an image with a giraffe, zebra and a lion even though they may classically have same amount of information or compressed file size. While we can build artificial systems that view it this way, can we go further and build solid theoretical frameworks, like it was done for communications about half a century ago. Let's see.